

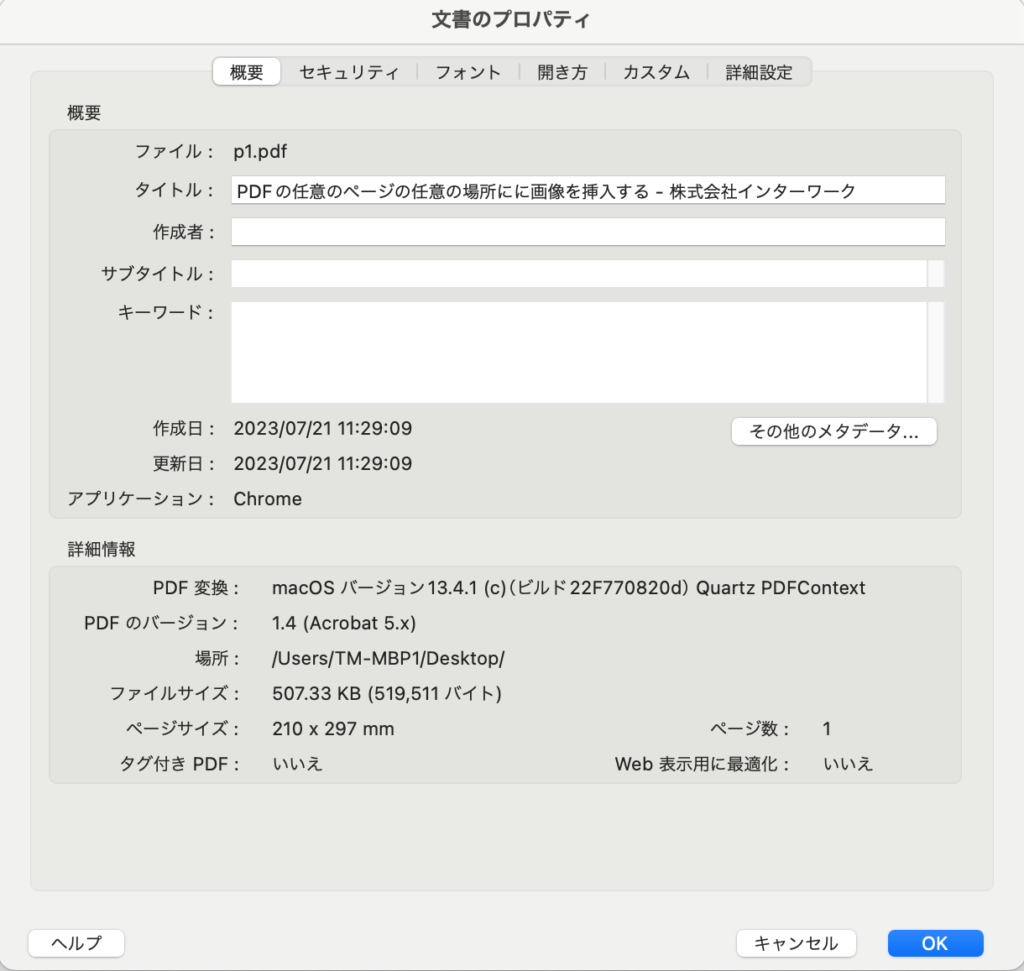
PDFファイルが構造化されているかどうかを確認するには、非常に簡単な方法があります。Adobe Acrobat Readerでファイルを開き、プロパティメニューを見てください。タグ付きPDFメニューオプション(詳細セクションの左下の項目)が、PDFにタグが含まれているかどうかを教えてくれます。この場合は含まれていません。
また、JPedalにはPDFUtilitiesクラスがあり、ファイルがPDF仕様に従って完全にタグ付けされているかどうかをプログラムでチェックすることができます。

JDELI – 幅広い画像フォーマットを読み書きするJava SDK
Javaでイメージファイルを安全に扱うJDeliは、HEICやその他のイメージファイル形式をJavaで簡単に読み書き、変換、操作、処理できるようにするJava SDKです。HEIC画像の読み出し/書き込みJDeliは、開発者にHEIC画像フォーマットの包括的なサポートを提供します。また、JPEG/JPEG2000、PNG、TIFFファイルを含む他の画像フォーマットのサポートも強化されています重要なファイルを安全に保管

